Ghosttyの設定をGUI(ghostty-config)で管理する方法
Katz
KALEIDOT OS

最近、ChatGPTやClaudeといったAIサービスを使うのが当たり前になってきましたが「オフライン環境でも使いたい」「API費用をかけずにローカルで動かしたい」と思うことがあります。
そうした要望を手軽に叶えてくれるのがOllamaというソフトウェアです。Ollamaを使えばGemma、Llama、Qwenなどを代表とするローカルLLMを自分のマシンで動かすことができます。
この記事では、Ollamaの導入から基本的な使い方までを紹介します。
Ollama は、ローカル環境でLLMを手軽に実行するためのオープンソースツールです。 アプリやコマンドでローカルLLMのダウンロードから実行までを簡単に行えます。

| 項目 | 内容 |
|---|---|
| 対応OS | macOS / Linux / Windows |
| インターフェース | GUI・CLIの両方から利用可能 |
| 対応ローカルLLM | Llama 3、Gemma 3、Mistral、Phi、Qwen など多数 |
| GPU対応 | NVIDIA / Apple Silicon に対応 |
必要なRAMはローカルLLMのサイズによって異なります。筆者の環境で動作確認したところ、サイズに応じて快適に使用するには以下のRAM容量が必要そうでした。
| サイズ | 必要RAM目安 | ローカルLLMの例 |
|---|---|---|
| 4B | 8GB | gemma3 (4B) |
| 12B | 16GB | gemma3 (12B) |
| 27B | 32GB以上 | gemma3 (27B) |
筆者環境:MacBook Pro / Apple M1 Pro (10コア) / RAM 32GB / macOS 26.3.1
Ollama公式サイト から macOS用の .dmg ファイルをダウンロードします。ダウンロードした .dmg ファイルを開き、Ollamaのアイコンを Applications フォルダへドラッグ&ドロップします。
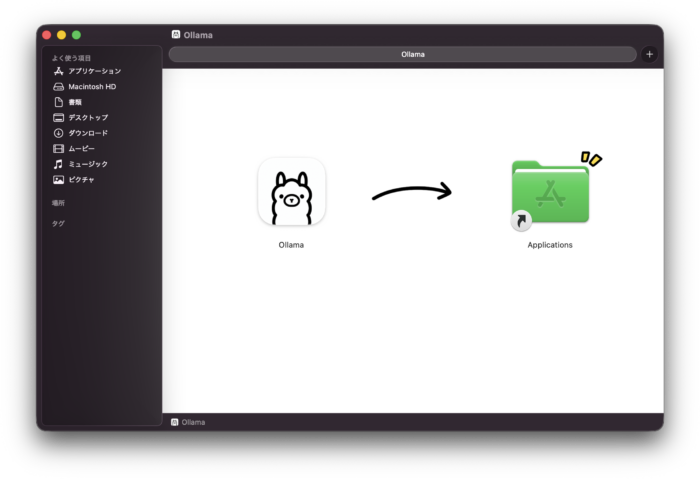
その後、アプリケーションフォルダからOllamaを起動すると、以下の画面が表示されて利用開始できます。
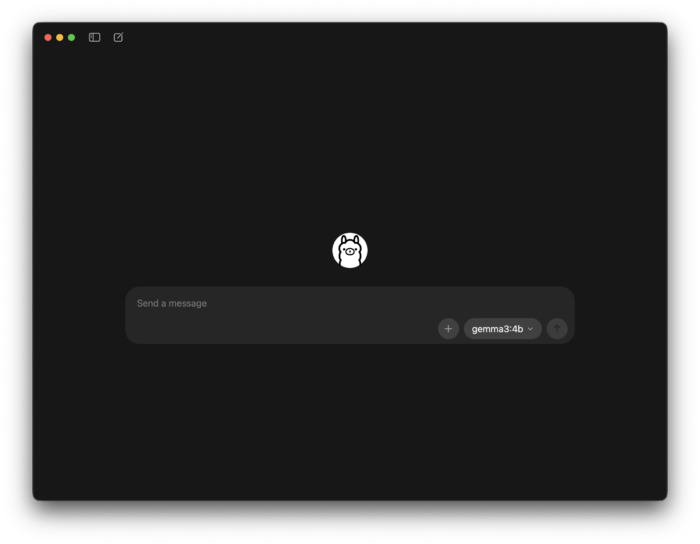
ローカルLLMをダウンロードするには、まずアプリのローカルLLM選択画面から、使用したいローカルLLMを選択します。
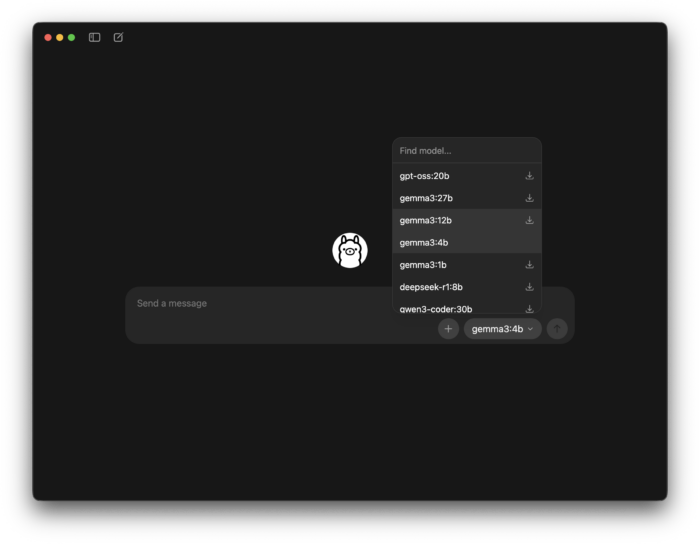
次に「Send a message」にテキストを入力して送信を実行すると、以下のようにダウンロードが開始されます。
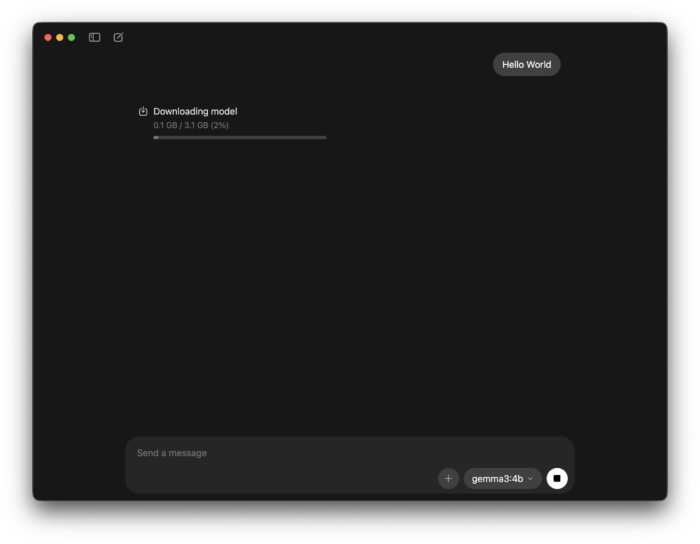
アプリではなくコマンドでダウンロードする場合は、ollama run <モデル名> を実行します。ローカルLLMのダウンロードと起動を同時に行えます。
% ollama run gemma3:12b
pulling manifest
pulling e8ad13eff07a: 89% ████████████████████████████████████████████████████████████████████████ ▏ 7.2 GB/8.1 GB 23 MB/s 37s現在起動しているローカルLLMはコマンドから確認できます。以下のコマンドを実行すると、起動中のローカルLLM名・使用メモリ・処理に使用しているプロセッサが一覧表示されます。
% ollama ps
NAME ID SIZE PROCESSOR CONTEXT UNTIL
gemma3:4b a2af6cc3eb7f 4.9 GB 100% GPU 32768 4 minutes from nowPROCESSOR 欄に 100% GPU と表示されていればApple SiliconのGPUで動作しています。CPUのみの場合は 100% CPU と表示されます。
起動したローカルLLMはバックグラウンドで動作し続けるため、使用後はメモリを占有し続けます。使用しないローカルLLMは以下のコマンドで停止してメモリを解放できます。
% ollama stop gemma3:12b停止後に ollama ps で確認すると、対象のローカルLLMが一覧から消えていることを確認できます。
% ollama ps
NAME ID SIZE PROCESSOR UNTILダウンロード済みのローカルLLMはコマンドから確認できます。以下のコマンドを実行するとローカルLLM名・サイズ・更新日時が一覧表示されます。
% ollama list
NAME ID SIZE MODIFIED
gemma3:12b f4031aab637d 8.1 GB 11 minutes ago
gemma3:4b a2af6cc3eb7f 3.3 GB 23 minutes ago特定のローカルLLMの詳細情報を確認したい場合は ollama show コマンドを使います。ローカルLLMのアーキテクチャやパラメータ数、コンテキストウィンドウのサイズなどを確認できます。
% ollama show gemma3:4b
Model
architecture gemma3
parameters 4.3B
context length 131072
embedding length 2560
quantization Q4_K_M
Capabilities
completion
vision
Parameters
stop "<end_of_turn>"
temperature 1
top_k 64
top_p 0.95
License
Gemma Terms of Use
Last modified: February 21, 2024
...ローカルLLMはファイルサイズが大きいため、不要になったものは削除してディスク容量を確保しましょう。削除は以下のコマンドで行います。
% ollama rm gemma3:12b
deleted 'gemma3:12b'削除後に ollama list で一覧を確認すると、対象のローカルLLMが消えていることを確認できます。
% ollama list
NAME ID SIZE MODIFIED
gemma3:4b a2af6cc3eb7f 3.3 GB 23 minutes agoこの記事では、Ollamaを使ってローカルLLMを自分のマシンで動かす方法を紹介しました。OllamaをインストールするとアプリとCLIが使えるようになり、アプリや以下のコマンドでローカルLLMを管理できます。
ollama run でローカルLLMをダウンロードして起動できるollama ps で起動中のローカルLLMを確認、ollama stop でメモリを解放できるollama list でダウンロード済みのローカルLLMを一覧表示、ollama show で詳細情報を確認できるollama rm で不要なローカルLLMを削除してディスク容量を確保できるOllamaを使えばクラウドに依存せず、プライバシーを守りながら、APIコストをかけずにローカルLLMを活用できます。まずは ollama run gemma3 などで試してみてください。